一、开始首次登陆MongoDB,由于没有设置用户管理权限,会给出警告,“WARNING: Access control is not enabled for the database”。警告(warning)和错误(error)不一样,你完全可以忽略警告,并不影响你使用...
”mongodb python 爬虫 scrapy“ 的搜索结果
创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.py title = scrapy.Field() position = scrapy.Field() publish_date = scrapy.Field() pipelines.py from pymongo import ...
python爬虫,Scrapy抓手机App数据并存入MongoDB(今日头条)python爬虫,Scrapy抓手机App数据并存入MongoDB(今日头条)python爬虫,Scrapy抓手机App数据并存入MongoDB(今日头条)python爬虫,Scrapy抓手机App数据...
创建项目scrapy startproject zhaoping创建爬虫cd zhaopingscrapy genspider hr zhaopingwang.com目录结构items.pytitle = scrapy.Field()position = scrapy.Field()publish_date = scrapy.Field()pipelines.pyfrom ...
这次我给大家讲讲如何使用scrapy连接到(SQLite,Mysql,Mongodb,Redis)数据库,并把爬取的数据存储到相应的数据库中。一、SQLite1.修改pipelines.py文件加入如下代码# 爬取到的数据写入到SQLite数据库import sqlite3...
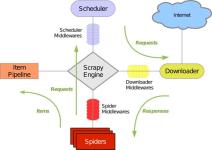
原标题:Scrapy爬虫之MongoDB数据存储在开始代码之前,还没有安装过MongoDB的朋友,可以先去官网下载并安装。MongoDB下载官网:https://www.mongodb.com/download-center;安装和使用教程:...
学习python时,爬虫是一种简单上手的方式,应该也是一个必经阶段。本项目用Scrapy框架实现了抓取豆瓣top250电影,并将图片及其它信息保存下来。爬取豆瓣top250电影不需要登录、没有JS解析、而且只有10页内容,用来练...
前一段(30天爬虫学习),我把数据都保存为Excel或csv格式。一方面数据看起来比较直观,Excel方便做数据提取、分析。另一个方面我对其他数据分析的工具不熟悉,昨天看一到篇用padans...Scrapy爬虫数据存到mongodb中...
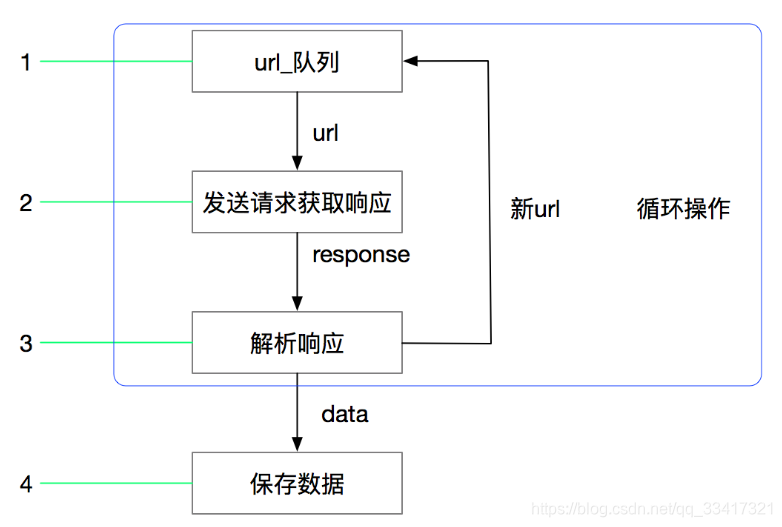
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中。items.py文件复制代码# -*- coding: utf-8 -*-import scrapyclass DoubanItem(scrapy.Item):# define the ...
sudo yum -y install mongodb-org安装问题:提示No package mongodb-org available。解决方案:编辑Mongodb安装源vim /etc/yum.repos.d/mongodb-org-3.6.repo编辑内容如下:[mongodb-org-3.6]name=MongoDB ...
目标抓取盗墓笔记小说网站上《盗墓笔记》这本书的书名、章节名、章节url,并存放到MongoDB中1.Scrapy中settings.py的设置(先scrapy startproject novelspider)在settings.py中配置MongoDB的IP地址、端口号、数据...
环境需求基础环境沿用之前的环境,只是增加了MongoDB(非关系型数据库)和PyMongo(Python 的 MongoDB 连接库),默认我认为大家都已经安装好并启动 了MongoDB 服务。测试爬虫效果我这里先写一个简单的爬虫,爬取...
爬虫开发阶段-爬虫基础-MongoDB数据库-爬虫Scrapy框架和案例.内有丰富的开发案例,希望对大家有用
1. Scrapy框架Scrapy是python下实现爬虫功能的框架,能够将数据解析、数据处理、数据存储合为一体功能的爬虫框架。2. Scrapy安装1. 安装依赖包yum install gcc libffi-devel python-devel openssl-devel -yyum ...
这个框架关注了很久,但是直到最近空了才仔细的看了下 这里我用的是scrapy0.24版本先来个成品好感受这个框架带来的便捷性,等这段时间慢慢整理下思绪再把最近学到的关于此框架的知识一一更新到博客来。最近想学git ...
本文为大家介绍利用python爬虫scrapy框架爬取药网,希望可以帮助到大家。 cmd 命令创建项目 scrapy startproject yiyaowang cd yiyaowang scrapy genspider yaowang yaowang.com 先进入settings.py文件将服从...
想着有些小伙伴在python学习的时候有点丢三落四的毛病,特意整理出来scrapy在python爬虫使用中需要注意的事项,大家一起看看吧。 1.如果需要大批量分布式爬取,建议采用Redis数据库存储,可安装scrapy-redis,使用...
1. Scrapy框架Scrapy是python下实现爬虫功能的框架,能够将数据解析、数据处理、数据存储合为一体功能的爬虫框架。2. Scrapy安装1. 安装依赖包yum install gcc libffi-devel python-devel openssl-devel -yyum ...
环境需求基础环境沿用之前的环境,只是增加了MongoDB(非关系型数据库)和PyMongo(Python 的 MongoDB 连接库),默认我认为大家都已经安装好并启动 了MongoDB 服务。测试爬虫效果我这里先写一个简单的爬虫,爬取...
下载与安装pip install scrapy创建项目scrapy startproject 项目名称这里我们指定的项目名称为Spider,执行完创建项目的命令后,得到的提示为:You can start your first spider with:cd Spiderscrapy genspider ...
最近自己用一个python里面非常常用的爬虫框架scrapy爬取豆瓣Top250电影榜单的一些数据,具体过程如下: 首先提前下载好一些库,最主要的是scrapy和selenium 第一: 开启一个scrapy项目,创建scrapy项目需要在命令行...
在安装Scrapy前首先需要确定的是已经安装好了Python(目前Scrapy支持Python2.5,Python2.6和Python2.7)。官方文档中介绍了三种方法进行安装,我采用的是使用 easy_install 进行安装,首先是下载Windows版本的...
python爬虫 python爬虫_爬虫项目实战之Scrapy抓手机今日头条App数据并存入MongoDB
经常看博客的同志知道,博客园每个栏目下面有200页,多了的数据他就不显示了,最多显示4000篇博客如何尽可能多的得到博客数据,是这篇...注意看URL链接https://zzk.cnblogs.com/s/blogpost?Keywords=python&datetime...
推荐文章
- linux c 串口 调用命令,Linux系统C语言串口收发-程序员宅基地
- 八:通过Infura部署到rinkeby测试网_使用infura运行测试网-程序员宅基地
- 『Android 技能篇』优雅的转场动画之 Transition-程序员宅基地
- Webshell绕过技巧分析之-base64编码和压缩编码-程序员宅基地
- 大一计算机思维知识点,大学计算机—基于计算思维知识点详解.docx-程序员宅基地
- 关于敏捷开发的一篇访谈录-程序员宅基地
- 挑战安卓和iOS!刚刚,华为官宣鸿蒙手机版,P40搭载演示曝光!高管现场表态:我们准备好了...-程序员宅基地
- 精选了20个Python实战项目(附源码),拿走就用!-程序员宅基地
- android在线图标生成工具,图标在线生成工具Android Asset Studio的使用-程序员宅基地
- android 无限轮播的广告位_轮播广告位-程序员宅基地